【摘要】本篇文章,将实现一个利用任意图床上传任意数据,搭建无限容量的网盘的一个方法。适合任何支持图片上传的平台。文章将使用百度识图的图片上传功能作为开放图床,实现储存数据的功能。前言首先,我觉得这个方法不具有太多的实用价值。但是我认为,这确实是一个好方法,可以使用在一些极...
本篇文章,将实现一个利用任意图床上传任意数据,搭建无限容量的网盘的一个方法。适合任何支持图片上传的平台。文章将使用百度识图的图片上传功能作为开放图床,实现储存数据的功能。
前言
首先,我觉得这个方法不具有太多的实用价值。但是我认为,这确实是一个好方法,可以使用在一些极端的环境下,甚至在某一些场合是一个很好的利器。
本篇文章将从原理去分析,然后再去实际的代码去实现相应的功能。文章中主要使用Golang和Python去实现相关的功能。不是该语言的使用者也无需担心,你看明白原理之后同样可以用你所熟知的语言去编写相关程。
原理概述
我们都知道,现在很多网站都提供图片上传功能,特别是一些免费图床网站,提供任意图片上传并分享链接的功能。这些图床站点可以说是非常多,随便在百度或者Google上搜索,总能找到各式各样的免费图床。有的提供api,有的没有提供api,还有的对图片上传大小有限制的等等。但是这些并不是限制因素,本文中的方法,图床站必须满足的是不对图片压缩,还有就是最好能长时间保存图片。
我们文章开头也说了,希望能在这些支持图片上传的网站,上传任意的数据。这显然是不可能的,图片站后端必定会对上传的格式进行验证,甚至有一些网站你直接把文件名改成XX.jpg上传也不行。虽然我们想要上传任意数据,但却只能上传图片格式的数据。想到这里我们不妨在图片上下功夫。
图片写入数据
也许很多人会想到,很早之前的一个方法。就是使用copy命令把压缩包文件,拷贝到jpg文件结尾,但是今天我们讲的不是这个方法。这里的方法是类似于二维码的原理,但是却能比二维码储存更多的信息。
二维码是把数据编码成方块的排列顺序,来达到记录数据的作用。所以带来的好处是可以允许图片压缩,可以直接用手机拍摄二维码解码。但是坏处是二维码本身的信息量大于编码前的信息量。比如说,一个hello只有5个字节,但却要用一张图片来储存。我们既然要上传到图床上来实现一个网盘,那这种编码的大小差距太大的方案肯定是不能选的。
因此,本文使用的方法,就是把数据编码到像素中,虽然说也会有大小的损失,但是相比与二维码已经好很多了。缺点是图片不能压缩,因为一旦把数据编码到像素级别,你破坏任何一个像素都会导致数据的丢失。
图片的每一个像素,都储存有颜色信息–RGB。我本文的例子中我使用的是每一种颜色8位,3种颜色一共24位,也就是说每个像素能保存3个字节的信息。一个1080 * 1080 像素的RGB图片能保存3499200Byte的数据也就是差不多3MByte的数据。
举个例子,同样是“hello”这段文本,它的16进制0x68 0x65 0x6c 0x6c 0x6f,然后3以3个为一组,划分出来。然而有时候并不能完美划分。比如这次,3个为一组的话就缺一个。
ASCII: h e l l o
16进制: 0×68 0×65 0x6c 0x6c 0x6f
10进制: 104 101 108 108 111
RGB: R G B R G
但是没关系,我们直接在后面补上0就好了,最后,原本的16进制就变成了0x68 0x65 0x6c 0x6c 0x6f 0x00,3个为一组,分成2组{0x68 0x65 0x6c} {0x6c 0x6f 0x00}对应到RGB后能产生2个像素。
数据读出
我们把每3个字节的信息写入每个像素中。如果要读出来,只需要反方向操作即可。
从左到右,从上至下依次读取每个像素的颜色信息,再把该颜色的RGB信息提取出来,按照RGB的顺序,一个字节一个字节读取出来,把读出来的数据写入到文件中,这个数据就能成功恢复。
实际应用
因为这个相关的功能我已经用代码写出来了,所以我这里直接用我写的程序来测试。后面的章节,详细的解释代码的构成。
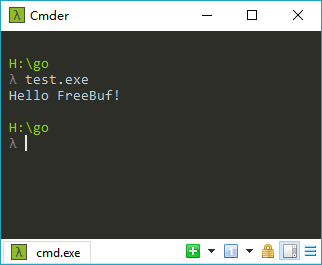
1.选出一个需要编码的文件,我这里用一个test.exe文件来作为例子!(运行即可输出“Hello FreeBuf”)
2.运行相关的编码程序,我这里是用自己写的程序IDII,运行后,显示成功~

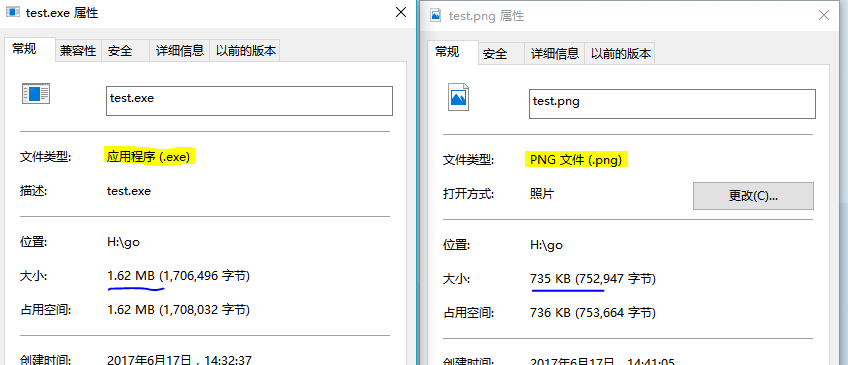
3.本地多了个test.png文件,这就是我们需要的编码后的文件。很壮观啊!(下面这个图片就是编码后的图片,但是因为传到freebuf图片被处理,所以你下载到本地无法还原回原来的文件~)
题外话,这里可以看出,exe文件有明显的层理结构,但我试过zip等压缩文件就是一堆乱七八糟点。
4.貌似png本身会对数据的冗余进行处理,比如这个例子中,我的png图片生成出来比原本的exe文件要小50%。
5.上传到图床中,本地保存一个外链地址。可以自己写一个上传文件的脚本,为了方便我自己用python来写,直接运行updataIMG.py文件,你可以看到文件成功上传了。

就像开头说的,我这里使用的是百度识图的一个图片上传的功能,抓包,然后找到接口,上传文件就能获取到一个外链地址,虽然结尾是一个jpg文件,不过实际测试发现并没有对文件内容进行修改,下载来,直接把后缀改成png,一样可直接解码。
http://e.hiphotos.baidu.com/image/pic/item/ac4bd11373f0820226f4cd7941fbfbedab641b15.jpg
百度图片外链地址可以试试看~
代码编写
本文使用的代码我已经全部上传到Github中了,有需要的朋友可以去看看。https://github.com/mscb402/imgcode
数据编码
数据编码部分的代码我直接用golang来实现,go是一个我很喜欢的语言,运行速度快还能直接跨平台编译。 为了方便调用,我在GOPATH的src目录下,新建一个叫”imgcode”的文件夹,再建立一个“imgcode.go”文件。取个包名为imgcode。
函数总览如下:
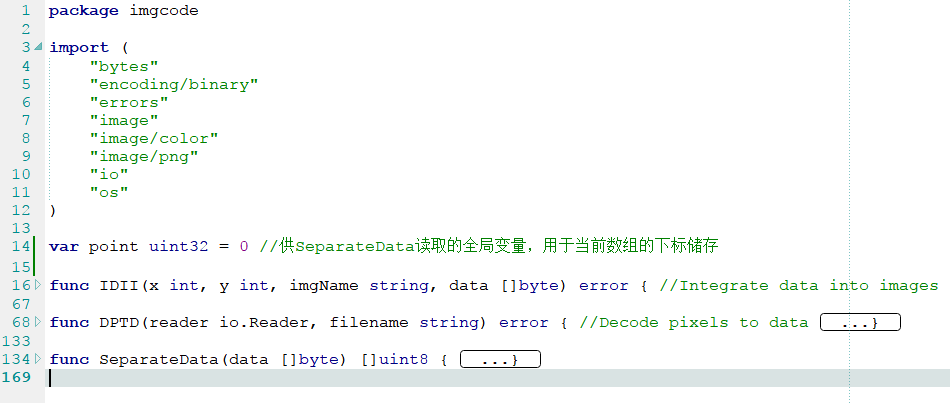
IDII 函数
全称为Integrate data into images,代码全景:

其中需要用到SeparateData函数,该函数的作用是自动对数据进行分组,每3个一组,不满足3个的补0.这里就不展示它的代码了,大家可以去我的github上查看完整代码。 IDII函数有4个参数分别是
x: 整数型 图片宽度
y: 整数型 图片长度
imgName: 字符串 图片文件地址
data: Byte 字节数组
函数开头判断相关参数是否正确。接着申请6个字节的内存,这是用来保存原文件的大小,这里前面讲原理的时候没有提到。保存文件的大小很必要的,因为我们前面也说了,数据是3个为一组,不满3个就补0,如果解码程序不知道文件的实际大小很有可能会把那个0也当成数据写入到文件,这会导致某些文件被破坏而无法打开。所以用6个字节(正好2个像素)保存文件大小的信息,基本上是够了,应该没有人丧心病狂的拿几个T的文件编码成一个png文件。
接下来的代码就是把这6个字节的数据写到原有数据的前面,然后建立一个指定像素大小的文件,每一个像素循环过去(从左至右,从上到下),上面我也画了个坐标轴,左上角是(0,0)。每一次写颜色值之前用SeparateData函数分配出3个数据出来,依次写到RGB三个颜色中。
然后就是把文件输出来。怎么样是不是很简单~~
数据解码
DPID函数
全称Decode pixels to data,代码全景(太长了分成2张):


DPID函数有2个参数分别是
reader: io.reader Golang的io文件读接口,即你调用的时候要先自己再代码里打开相应的图片文件,再把接口传给该函数
filename: 字符串 解码后文件的保存地址,注意如果是已经存在的文件会报错
代码开始对png文件解码,获取png文件像素的长宽信息,直接读取(0,0) (1,0)2个像素的值,因为之前我们在最开始的2个像素保存了文件的长度信息。 接着根据filename信息创建文件,并根据size信息填充文件大小。
最后根据刚才得到的像素的长宽进行循环,开头我们已经读取了2个像素了,所以前2个是无效数据,我们代码里判断当前的坐标,如果是(0,0) (1,0)就跳过,不是的话就读取出来然后解码。最后,就是判断已经解码的数据大小FilePointer和文件的大小size对比。一旦已读取到的数据已经达到编码前文件的大小,就立刻退出循环,结束解码。
原因我前面也说了,一旦一不小心多读了一个字节的代码,可能会出现文件出现无法打开问题。
调用实例
IDII调用实例
这里有一个小技巧,就是让程序自己控制长宽,用一个小公式就可以了 f(x)=1+(x/3)^(1/2)算出适合该文件编码的正方形图片xy大小。
package main import ( "fmt" "imgcode" "math" "os" ) func main() {
f, err := os.Open("test.exe")//要编码的文件 if err != nil {
fmt.Println(err) return }
defer f.Close()
fileData := make([]byte, 1024*1024*10) //1Kb=1024byte,1Mb=1024Kb 默认最大读取10M的文件进行编码 count, err := f.Read(fileData)
xy := int(math.Sqrt(float64(count/3))) + 1 err = imgcode.IDII(xy, xy, "test.png", fileData[:count])//要输出的png图片 if err != nil {
fmt.Println(err)
return }
fmt.Println("成功!")
} DPID函数调用实例
package main
import ( "imgcode" "fmt" "os" )
func main() {
f, err := os.Open("test.png")//要解码的图片 if err != nil {
fmt.Println(err) return }
defer f.Close()
err = DPTD(f, "out.out")//解码后文件的保存地址 if err != nil {
fmt.Println(err) return }
} 以上代码我就不再讲解了,大家有兴趣的可以自己整合一下,加个flage参数等等
上传百度识图代码
代码实例:

百度识图有一个上传接口就是http://image.baidu.com/pictureup/uploadshitu这个地址,大家可以自行研究!
实现网盘功能
事实上,如果我们希望能实现一个没有指定服务器的“云网盘”,是完全没有问题的。我们需要手中掌握一定的资源——支持图片上传且符合要求的图片上传站。
比如说,如果我手中有100个可以上传图片的网站,且都能很方便的用python去上传文件,那我们就可以把一个100M的视频文件分割成10个10M的文件,然后把每一个含有相同数据的图片用脚本上传到其中的30%的图片节点中,本地新设计一个保存文件的结构,比如{"test.png":{1:"URL_XXX",2:"xxx",3:"xxx"}}。当你要提取test.png文件时,解析本地的保存的配置信息,下载相关节点的图片(30%节点保存同一个数据,有一定的容灾机制),合成即可!
如果手里的资源无限,理论上上传的文件大小也是无限,至于保存时间嘛!最好也能定期的检查相关站点是否还能访问,尽快的备份到其他剩余节点。
以上我说的都可以用程序来实现自动化。 这么一说,实际上有点像p2p的文件分发原理。
无论如何,这个是一个很有意思的小玩意,还有很多的潜能等待着你去挖掘。
总结
其实文中说的这个图片保存数据的方法并不新鲜,在国内外很早就有人提出这种方法,我一直觉得这是一个非常有趣的技巧。挖掘空间很大。比如我们可以用来传输一些加密后的文件,或者朋友之间传输文件。也许有人问了,我搞了半天,为什么不自己把数据存到网盘里呢?对呀!为什么呢…
本文所以代码你可以在我的Github里找到:https://github.com/mscb402/imgcode
参考文献
http://www.iamcal.com/png-store/
https://www.cnblogs.com/index-html/p/canvas_data_compress.html
*本文原创作者:mscb
小东
简介:专业团队网站开发、安全运维,合作意向请联系!













{kind=link}
发表评论